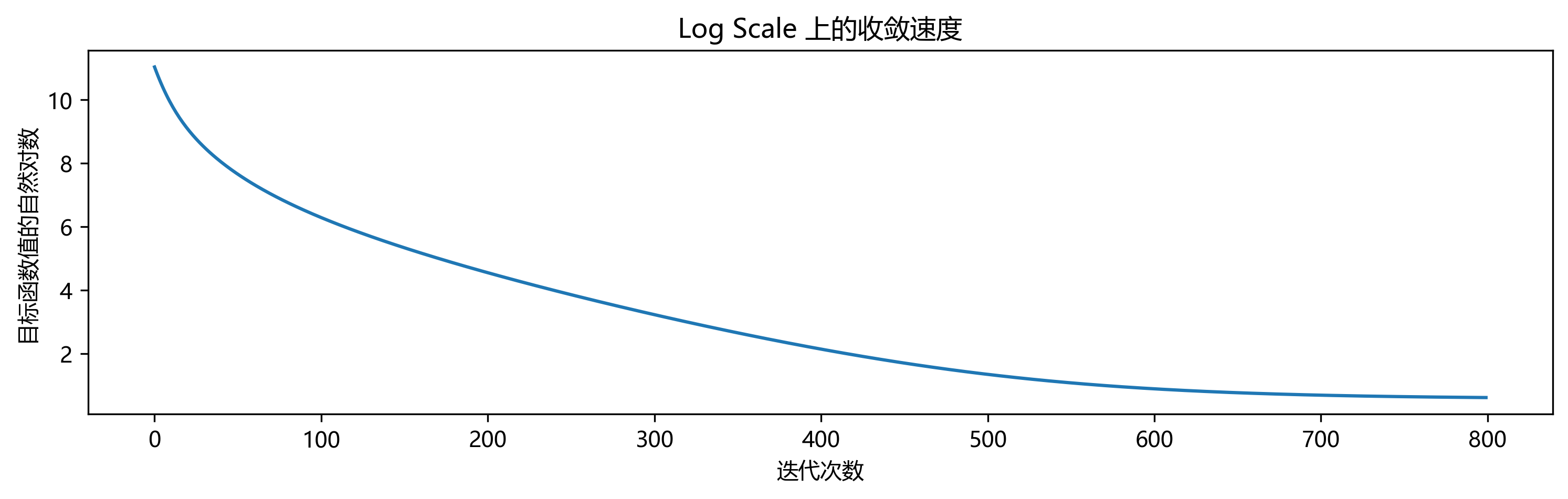
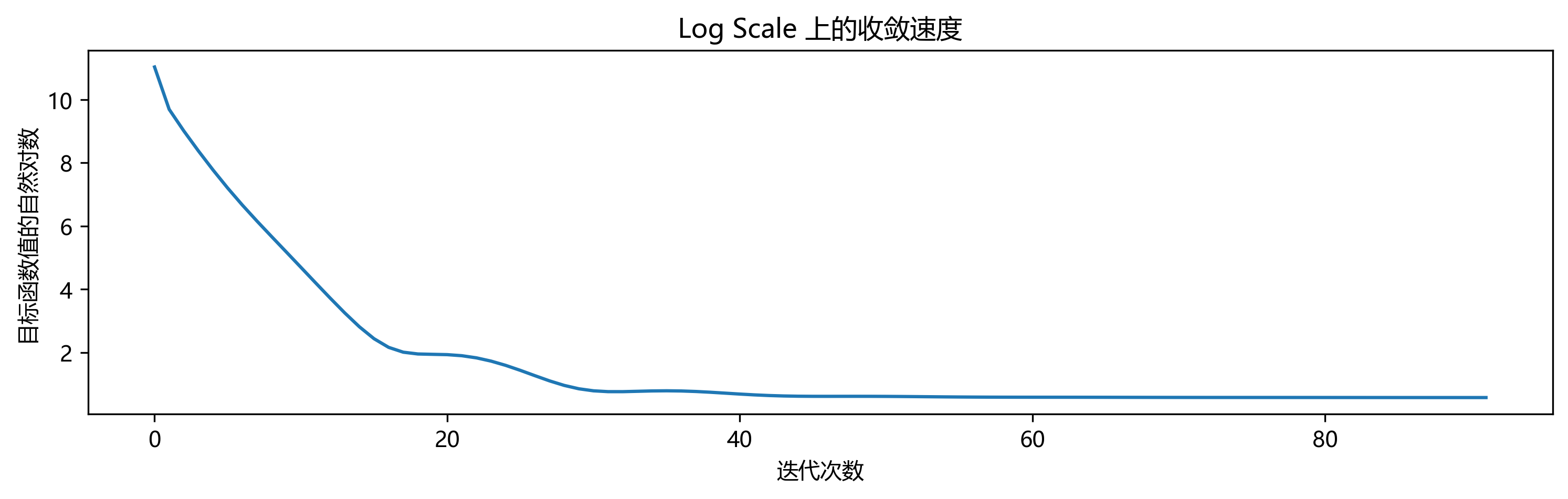
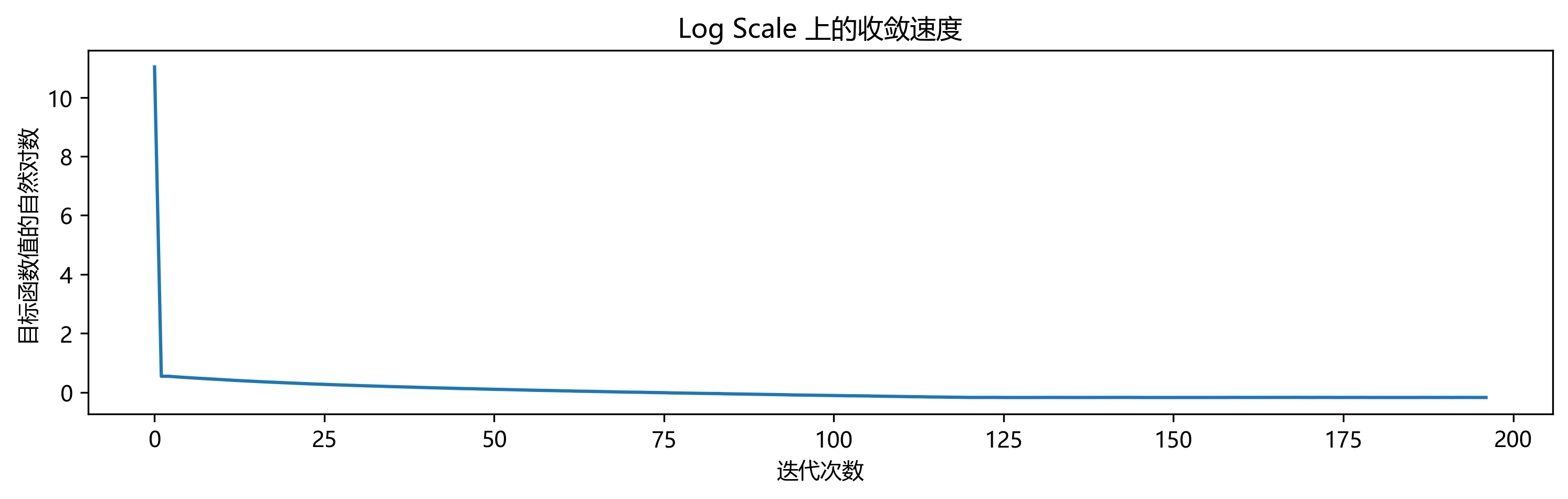
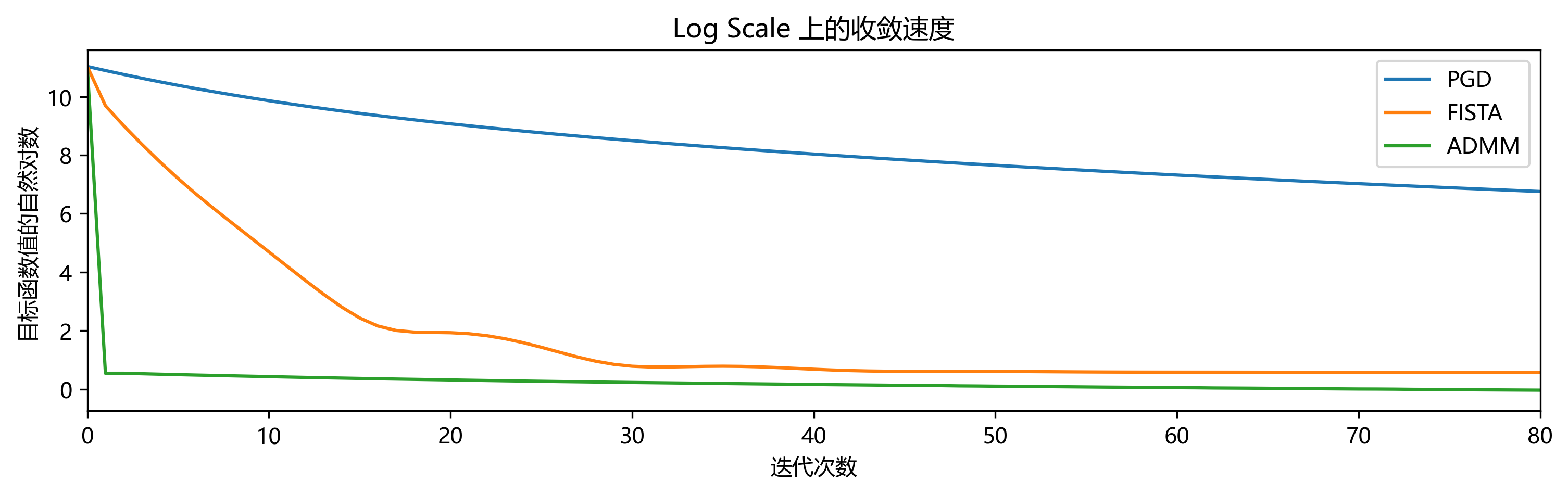
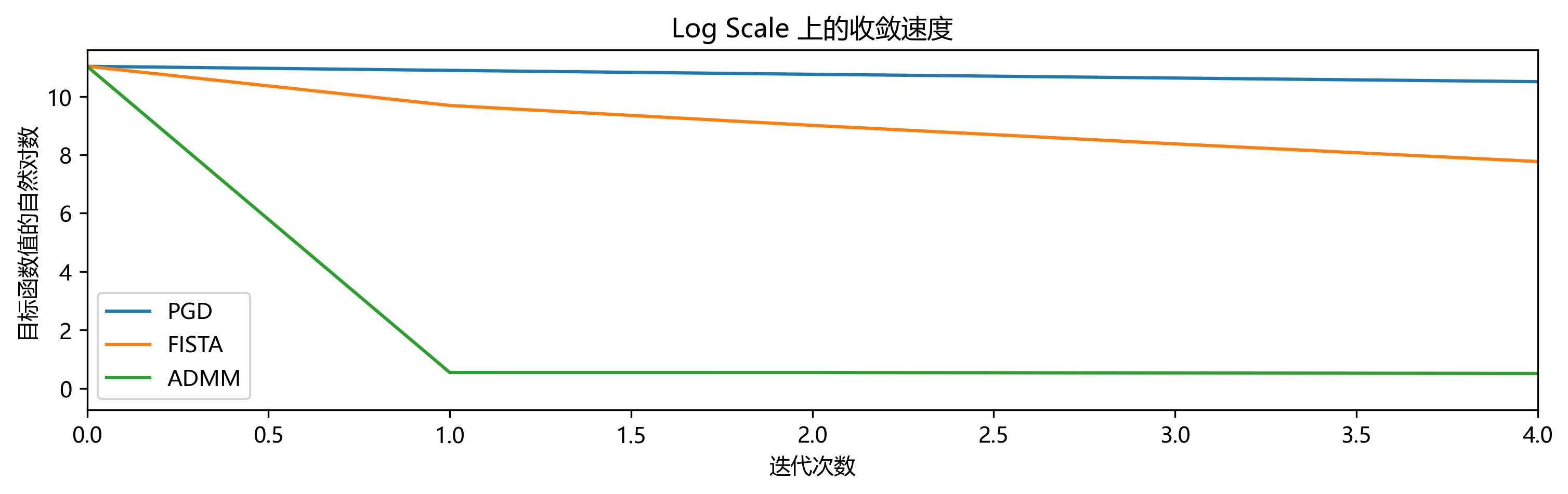
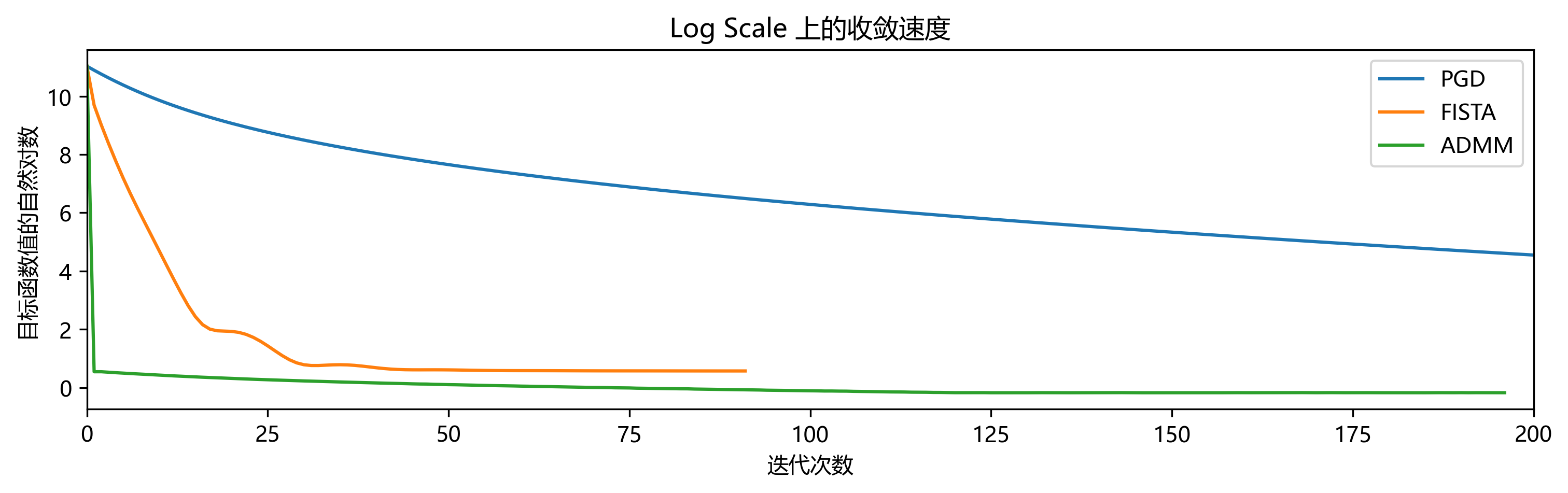
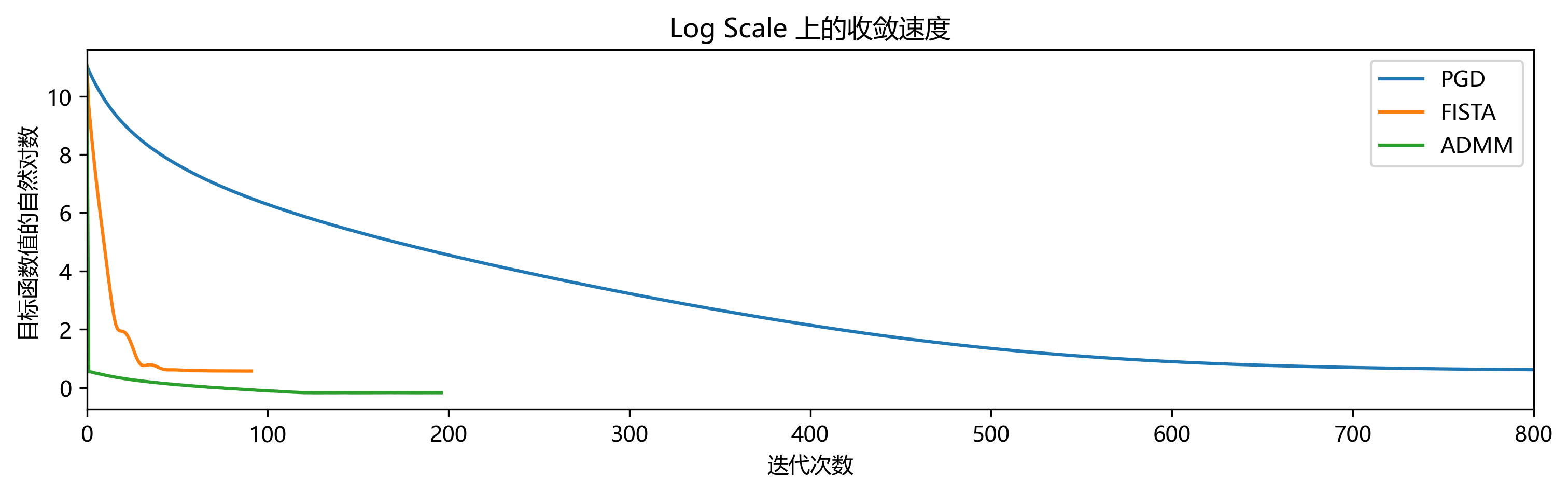
Nesterov 加速
也即 FISTA
将书上的 notation 改成本题使用的,中文教材 条件 (8.2.2) 可写成
(同时也是参考课件《06-近端梯度下降与加速》第 26 页的写法)
g(x^+) \geq g(v) + \nabla g(v)^T (x^+ -v) + \dfrac{1}{2t} \|x^+ -v\|^2_2
若转换成代码,其中 x^+ 写作 x_new,v 写作 x_v, 即转换为
g(x_new) <= ( gg + torch.sum( x_v.grad * (x_new - x_v) )
+ ( 1/(2*t) ) * ( torch.norm( x_new - x_v,ord=2,dim=0 ) )**2
)
相应地,x^{(x-1)} 写作 x_old,
v=x^{(x-1)} + \dfrac{k-2}{k+1}
\left(x^{(k-1)} - x^{(k-2)}\right)
x^{(k)} = \operatorname{prox}_{t_k}
\left(
v - t_k \nabla g(v)
\right)
写作
x_v = ( x + (i-2)/(i+1)*(x-x_old) )
x_new = S(x_v-t*x_v.grad,t)
def FISTA(x,max_iter=max_iter,beta=beta,eps=epsilon,t=t):
f_all=[]
x_all=[]
x_all.append( x.clone().detach().numpy() )
x_old = x.clone().detach()
x_old.requires_grad = True; x_old.requires_grad_(True)
for i in range(1,int(max_iter)+1): # 不能从 0 开始
# FISTA 两阶段法的第一阶段,沿前两步方向找一个新的点
x_v = ( x + (i-2)/(i+1)*(x-x_old) )
x_v = x_v.clone().detach().requires_grad_(True)
gg=g(x_v); ff=f(x)
f_all.append(ff)
gg.backward()
x_old.requires_grad = True; x_old.requires_grad_(True)
while True:
with torch.no_grad():
# 这是个上下文管理器,表示在这个缩进块内不需要计算梯度
# 更新参数不需要梯度
x_new = S(x_v-t*x_v.grad,t)
if g(x_new) <= (
gg + torch.sum( x_v.grad * (x_new - x_v) )
+ ( 1/(2*t) ) * ( torch.norm( x_new - x_v,p=2,dim=0 ) )**2
):
# 一旦满足回溯线搜索想要的条件,就接受这个新的参数作为更新,并退出
x_old = x.clone().detach()
x = x_new
break
# 如果不满足(免于退出),就缩减步长,然后又看需不需要再缩减
t=t*beta
x_all.append(x.clone().detach().numpy())
iter_norm = torch.abs(torch.norm(x) - torch.norm(x_old))
if iter_norm < eps:
return x, f_all, x_all
return x, f_all, x_all
交替方向乘子法
从 Stephen P. Boyd 等人的 Slides(September 2010)第 17 页得知,在 ADMM 算法迭代中,
对于 \dfrac{1}{2} \|Ax-b\|_2^2 + \lambda \|x\|_1 有
\begin{aligned}
x^{(k+1)}&:=(A^TA+\rho I)^{-1}(A^Tb+\rho z^{(k)}-y^{(k)})
\\
z^{(k+1)}&:=S_{\lambda/\rho}(x^{(k+1)}+y^{(k)}/\rho)
\\
y^{(k+1)}&:=y^{(k)}+\rho(x^{k+1}-z^{(k+1)})
\end{aligned}
但是,这里的二次可微项系数是 \frac{1}{2},我们求解问题的二次可微项系数是 1,不可直接照搬
以下从原问题出发重新推导所求问题
记 g(x)=\|Ax-b\|^2_2 \quad h(x)=\mu \|x\|_1 \quad f(x)=g(x)+h(x)
则原问题写作 \enspace \min_x f(x)
现改写为 \enspace \min_{x,z} g(x)+h(z) \quad \text{s. t.} \enspace x-z=0
若 x-z=0 化为 A_1 x + A_2 z = b 的标准形式,则 \begin{cases}
A_1&=1
\\
A_2&=-1
\\
b&=0
\end{cases}
记 Lagrange 乘子为 y \quad 罚因子为 \rho \quad 固定步长为 \tau
对改写形式构造增广 Lagrange 函数
L_\rho = g(x)+h(z)+ y^T (x-z) + \frac{\rho}{2} \|x-z\|^2_2
对于每次迭代
第一步
\begin{aligned}
x^{(k+1)}&=\operatorname{argmin}_x L_\rho (x,z^{(k)},y^{(k)})
\\
&=\operatorname{argmin}_x \left\{
\|Ax-b\|^2_2 +\mu \|z\|_1 +(y^{(k)})^T (x-z^{(k)}) + \frac{\rho}{2} \|x-z^{(k)}\|^2_2
\right\}
\\
\Rightarrow \quad& \frac{\partial L}{\partial x} = 2 A^T (Ax-b) +y^{(k)} +\rho(x-z^{(k)})
\\
\text{令 } \frac{\partial L}{\partial x} &=0 \text{ 则 }
2 A^T Ax - 2A^T b +y^{(k)} + \rho x - \rho z^{(k)} =0
\\
\Rightarrow \quad& (2 A^T A + \rho I)x - 2 A^T b + y^{(k)} - \rho z^{(k)} =0
\\
\Rightarrow \quad& (2 A^T A + \rho I)x = 2 A^T b + \rho z^{(k)} - y^{(k)}
\\
\Rightarrow \quad& x^{(k+1)}= (2 A^T A + \rho I)^{-1} (2 A^T b + \rho z^{(k)} - y^{(k)})
\end{aligned}
第二步
\begin{aligned}
z^{(k+1)}&=\operatorname{argmin}_z L_\rho \left( x^{(k+1)},z,y^{(k)} \right)
\\
&=\operatorname{argmin}_z\left\{
\|Ax^{(k+1)} -b\|^2_2 +\mu \|z\|_1
+ (y^{(k)})^T (x^{(k+1)}-z)
+ \frac{\rho}{2} \|x^{(k+1)}-z\|^2_2
\right\}
\\
&=\operatorname{argmin}_z\left\{
\mu \|z\|_1
+ (y^{(k)})^T (x^{(k+1)}-z)
+ \frac{\rho}{2} \|x^{(k+1)}-z\|^2_2
\right\}
\\ \quad \\
&\text{对要找最值点的目标乘以常数} \frac{2}{\rho}
\\ \quad \\
&=\operatorname{argmin}_z\left\{
\frac{2 \mu}{\rho} \|z\|_1
+ \frac{2}{\rho} (y^{(k)})^T (x^{(k+1)}-z)
+ \|x^{(k+1)}-z\|^2_2
\right\}
\\ \quad \\
&=\operatorname{argmin}_z\left\{
\frac{2 \mu}{\rho} \|z\|_1
+ 2 \left(\frac{y^{(k)}}{\rho}\right)^T (x^{(k+1)}-z)
+ \|x^{(k+1)}-z\|^2_2
\right\}
\\ \quad \\
&\text{加上与 } z \text{ 无关的项 } \left\|\frac{y^{(k)}}{\rho}\right\|^2_2
\\ \quad \\
&=\operatorname{argmin}_z\left\{
\frac{2 \mu}{\rho} \|z\|_1
+ \left\|\frac{y^{(k)}}{\rho}\right\|^2_2
+ 2 \left(\frac{y^{(k)}}{\rho}\right)^T (x^{(k+1)}-z)
+ \|x^{(k+1)}-z\|^2_2
\right\}
\\ \quad \\
&=\operatorname{argmin}_z\left\{
\frac{2 \mu}{\rho} \|z\|_1
+ \left\|
\frac{y^{(k)}}{\rho}
+ x^{(k+1)}-z
\right\|^2_2
\right\}
\\ \quad \\
&=\operatorname{argmin}_z\left\{
\frac{1}{2} \left\|
z-\left(
x^{(k+1)} + \frac{y^{(k)}}{\rho}
\right)
\right\|^2_2
+\frac{\mu}{\rho} \|z\|_1
\right\}
\\ \quad \\
&=S_{\left(\frac{\mu}{\rho}\right)} \left(
x^{(k+1)}+\frac{y^{(k)}}{\rho}
\right)
\qquad \text{其中 } S_{(\cdot)} (\cdot) \text{ 表示软阈值算子}
\end{aligned}
第三步
y^{(k+1)}=y^{(k)}+\tau \rho (x^{(k+1)}-z^{(k+1)})
总结
\begin{aligned}
x^{(k+1)}&= (2 A^T A + \rho I)^{-1} (2 A^T b + \rho z^{(k)} - y^{(k)})
\\ \quad \\
z^{(k+1)}&=S_{\left(\frac{\mu}{\rho}\right)} \left(
x^{(k+1)}+\frac{y^{(k)}}{\rho}
\right)
\\ \quad \\
y^{(k+1)}&=y^{(k)}+\tau \rho (x^{(k+1)}-z^{(k+1)})
\end{aligned}
def ADMM(x,max_iter=max_iter,eps=epsilon,t=t,rho=rho):
f_all=[]
x_all=[]
x_all.append( x.clone().detach().numpy() )
z = x.clone().detach()
z.requires_grad = True; z.requires_grad_(True)
y = torch.zeros_like(x) # 初始的 Lagrange 乘子设为零,形状和 x 对齐
for i in range(1,int(max_iter)+1):
# calculate the loss
ff = g(x) + h(z)
f_all.append(ff)
x_old = x.clone().detach()
x = torch.linalg.inv(2* A.T @ A + rho*torch.eye(n)) @ (2*A.T @ b + rho*z -y)
z = SS(x+y/rho,mu/rho)
y = y + tau * rho * (x-z)
iter_norm = torch.abs(torch.norm(x) - torch.norm(x_old))
if iter_norm < eps:
return x, f_all, x_all
x_all.append(x.data.cpu().numpy())
return x, f_all, x_all